ER-Reason
A Benchmark Dataset for LLM-Based Clinical Reasoning in the Emergency Room
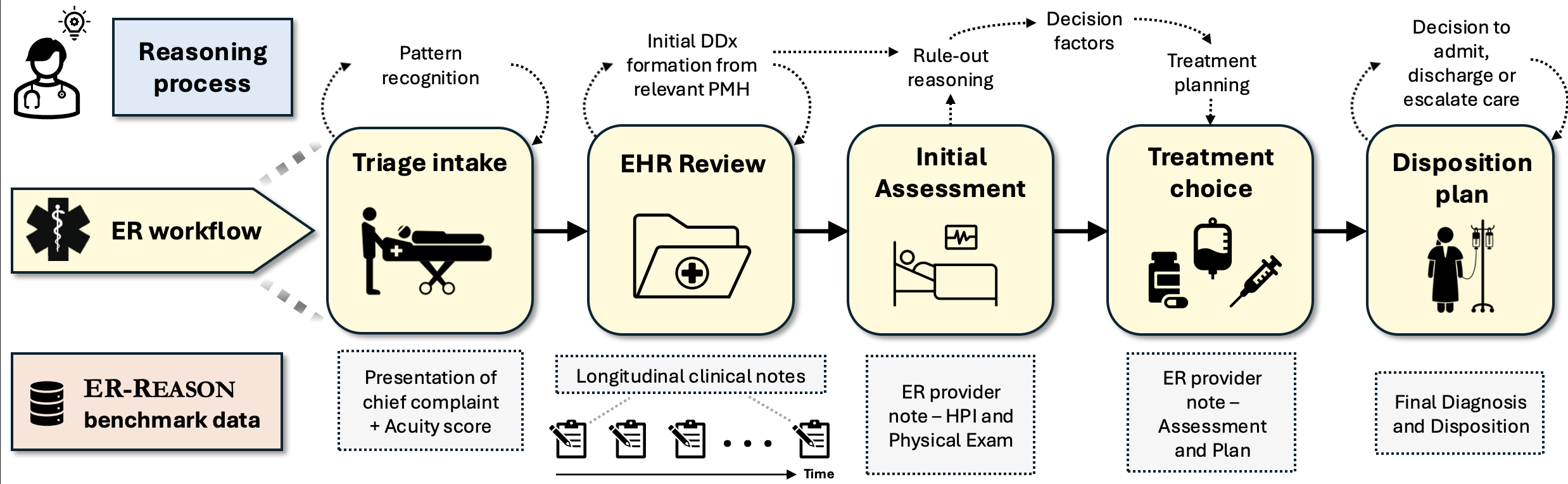
Large language models (LLMs) are increasingly applied to the field of medicine, but most benchmarks focus on narrow, exam-style medical question-answering rather than full clinical reasoning. ER-Reason captures the end-to-end emergency room (ER) decision-making pipeline, designed to test how well LLMs can approximate the complex, real-world reasoning of clinicians in high-stakes settings.
Key Components
Dataset
- 3,984 patients across 3,984 ER encounters
- 25,174 de-identified clinical notes
- Diverse note types: discharge summaries, progress notes, imaging reports, consult notes, echocardiography reports, and ER provider documentation
Workflow-Aligned Tasks
This benchmark is structured around five key stages of the ER workflow:
- Triage Intake: initial review of patient presentation and acuity scoring
- Assessment: summarization of patient's medical history in longitudinal notes
- Treatment Planning: assessment of differential diagnoses and clinical decision factors
- Disposition: determination of whether the patient should be discharged, admitted, observed, or transferred
- Final Diagnosis: formulation of the patient's final diagnosis
Physician-Authored Rationales
- Includes 72 expert-authored rationales covering rule-out reasoning, decision factors, and treatment planning.
- Provides a rare “gold standard” for evaluating reasoning in clinical decision-making, often missing from traditional EHR data.
ER-Reason represents a major step forward in benchmarking the real-world applicability of LLMs in emergency care. By moving beyond factual recall, it evaluates models on true clinical reasoning, pattern recognition, and decision-making under realistic conditions.